
Puppeteerは、人形遣いという意味ですが、Webの世界では、Chromium(Chrome)を自動化するNode.jsで動作するライブラリのことです。
GoogleのChrome DevTools Teamが作りました。
ChromiumはGoogle Chrome、Opera、Microsoft Edgeなど多くのブラウザのベースになっています。
詳しくは、こちらをご覧ください!

スクレイピングは、Wikipediaをみると以下です。
ウェブスクレイピング(英: Web scraping)とは、ウェブサイトから情報を抽出するコンピュータソフトウェア技術のこと。ウェブ・クローラー[1]あるいはウェブ・スパイダー[2]とも呼ばれる。 通常このようなソフトウェアプログラムは低レベルのHTTPを実装することで、もしくはウェブブラウザを埋め込むことによって、WWWのコンテンツを取得する。
Wikipedia スクレイピング
つまり、様々なWebサイトの情報を自動でとって来ることができるプログラム技術のことを言います。
例えば、映画評価サイトから映画のタイトルをごそっと取得してきたりできます。
スクレイピングを習得すると、どこかのサイトの特定の情報を取得し、加工まで行うことが可能になります。
スクレイピングは、Pythonも得意なのですがNode.jsでもモジュールを使うことで簡単に実施することが可能です。それが、Puppeteerです。
ただし注意しないといけないのは、人様のサイトにアクセスをして取得したいものをとってくるということになるので、無意識で大量アタックしていないかに気を配らないといけません。
- アクセスが同時多発的になっていないか
- 頻繁なアクセスを起こしていないか
上記を頭に置き、今回は、以下の探し方を紹介していきます。1から順番に方法を検討していくのが効率的です。
- idで探す
- classで探す
- タグで探す
- nameで探す
- 属性名で探す
- DOMツリーで探す
- ページをたどる
idで探す
idは、同一ページの中に1つだけ定義となっているので、idを指定すれば要素を1つに特定して取得できます。
最も基本的かつ安全で最初に試すべきがidを指定する事といえます。

Puppeteerを使うとこんな感じのJavaScriptになります。
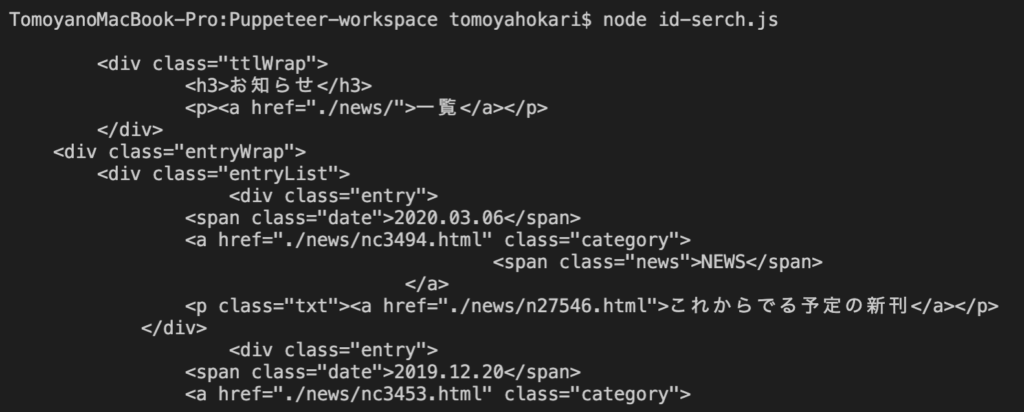
注目は、await page.goto();の部分からです。対象のページに移動し、指定のidの表示を待ち、表示されたらそのid を取得、指定idの範囲をHTMLとしてlogに出す。というコードです。
const puppeteer = require('puppeteer');
/**
* メインロジック.
*/
(async () => {
// Puppeteerの起動.
const browser = await puppeteer.launch({
headless: false, // Headlessモードで起動するかどうか.
slowMo: 50, // 指定のミリ秒スローモーションで実行する.
});
// 新しい空のページを開く.
const page = await browser.newPage();
// view portの設定.
await page.setViewport({
width: 1200,
height: 800,
});
// 秀和システムのページへ遷移.
await page.goto('https://www.shuwasystem.co.jp/');
// id="newsBlock" の要素の表示を待つ.
await page.waitForSelector('#newsBlock');
// 要素の取得.
const newsBlock = await page.evaluate((selector) => {
// evaluateメソッドに渡す第1引数のfunctionは、第2引数として渡したパラメータをselectorに引き継いでブラウザ内で実行する。
return document.querySelector(selector).innerHTML;
}, '#newsBlock');
console.log(newsBlock);
// ブラウザの終了.
await browser.close();
})();実際のアウトプットはこのようになります。
classで探す
idの次に確認するのがこのclassです。classを指定して、要素を特定していきます。
※要素を辿れるidがどこかにある場合はこの方法がいいのですが、全くidがない場合は、使えません。DOMツリーを順番に辿っていくことになります。

Puppeteerのセレクタにclalss指定をする場合は、.をつけます。
例としてコードを記載します。viewportの設定までは上のidのコードと同じです。Googleカスタム検索の表示を待ち、そこに文字を入力し検索するというコードです。
// とあるページへ遷移.
await page.goto('https://www.webdesignleaves.com/');
// Googleカスタム検索窓 の表示を待つ.
await page.waitForSelector('#cse-search-box .form-control');
// Googleカスタム検索窓 に Puppeteer とキーボード入力を行う.
await page.type('#cse-search-box .form-control', 'Puppeteer');
// inputのvalueを取得し、クリックを行う
await page.evaluate(() => {
document.querySelector('input[value="検索"]').click();
});とあるページに行き、id=cse-search-box要素配下のclass=“form-control’);”要素の表示を待ちます。
要素が表示されたら、そこに Puppeteer と入力します。
次に検索ボタンを押すためにvalueの値を取得しクリックをします。
結構簡単ですね!
☆ちなみに、オブジェクト指向プログラミングのclassと、html/JavaScriptのclassは全く異なり、オブジェクト指向プログラミングのclassはオブジェクトの型を指定するもの。(データ型からオブジェクトを生成する素になる)html/JavaScriptのclassは単に養素の装飾や特定のために利用するものです。
タグで探す
idもタグも指定がない場合は、htmlタグで探すことになります。
タグの場合はそのままタグ名を指定すればいいのでわかりやすいですが、便利な半面、要素を1つに特定したい場合は工夫が必要。(タグが階層状に複数存在するため)

そこで、class名との組み合わせが有効的になります。
classで使ったページで同じ動作を タグで探す方法でやると以下のようになります。(viewportの設定までは上のidのコードと同じです。)
// とあるページへ遷移.
await page.goto('https://www.webdesignleaves.com/');
// Googleカスタム検索窓 の表示を待つ.(inputタグのclass名form-controlを指定)
await page.waitForSelector('input.form-control');
// Googleカスタム検索窓 に Puppeteer とキーボード入力を行う.(inputタグのclass名form-controlを指定)
await page.type('input.form-control', 'Puppeteer');
// buttonタグを特定してクリックする.(inputタグのvalueの値が"検索"を指定)
await page.click('input[value="検索"]');nameで探す
name属性の値を指定して要素を特定します。
[属性名 = 値]
例
<input type="text" name="targetInput" />の場合は、
'input[name="targetInput"]'となります。
Googleの検索でPuppeteerを検索する場合は、このようになります。(viewportの設定までは上のidのコードと同じです。)
// googleのWebページにアクセス
await page.goto('http://www.google.co.jp/');
// 検索窓のテキストボックスに「Puppeteer」を入力
await page.type('input[name="q"]', 'Puppeteer');
// 検索ボタンをクリック
await page.click('input[value="Google 検索"]');livedoorの検索でPuppeteerを検索する場合は、はこのようになります。(viewportの設定までは上のidのコードと同じです。)
// Livedoorのトップページへ遷移し、ロードが完了するまで待つ.
await page.goto('http://www.livedoor.com/', { waitUntil: 'load' });
// 検索窓にPuppeteerと入力する.
await page.type('input[name="q"]', 'Puppeteer');
// 検索ボタンをクリックする.
await page.click('#acSubmitButton');属性名で探す
属性名は、例えばname属性であれば
[name="targetInput"]となります。
<div class=“spaceship” data-ship-id=“84721”
data-weapons=“…”みたいな場合は、以下のような指定の仕方になります。
await page.waitForSelector(‘[data-ship-id=“84721”]’);DOMツリーで探す
最終手段としてDOMツリーでの特定ができます。
DOMとは「Document Object Model」の略で、プログラムからHTMLやXMLを自由に操作するための仕組みのことを言います。HTMLとXMLをプログラムから扱えるようにしたAPIとも言われます。
DOMはツリー構造になっていて、それをDOMツリーと言います。
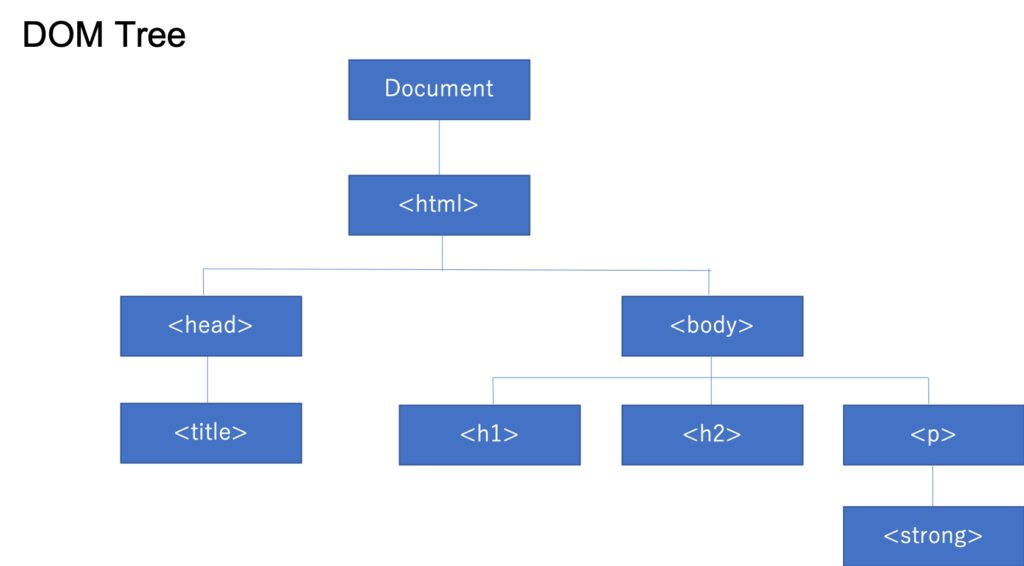
このDOMツリーは、ディベロッパーツールから確認できます。
ディベロッパーツールのElementsのところです。

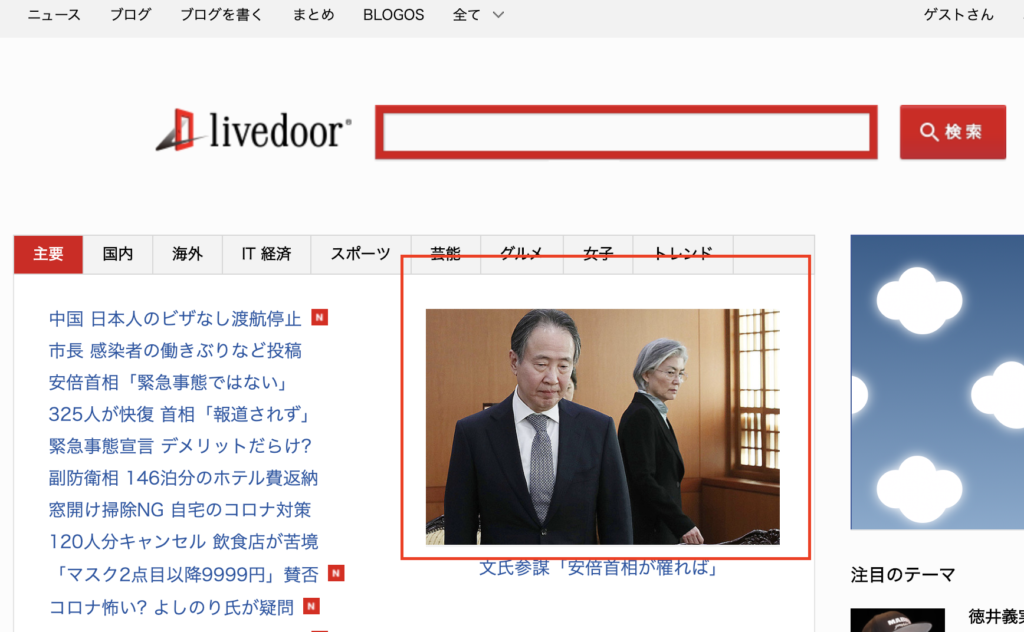
例のコードを書いてみます。livedoorのトップの記事画像を取得しています。(指定したidが記事ごとに変わっていくようなのでちょっとイマイチ。。。)
// Livedoorのトップページへ遷移.
await page.goto('http://www.livedoor.com/');
// id="newbook" の配下の img タグを取得する.
const newbookImages = await page.$$('#headline_img_3_344415');
// 取得した各imgタグへの処理.
for (imgTag of newbookImages) {
// 取得したタグのsrc属性を取得する. (取得した属性は JSHandle というオブジェクトで取得できる.)
const prop = await imgTag.getProperty('src');
// JSHandleオブジェクトの内容をjsonValueで取り出す. (この場合は文字列がsrcに指定しているurlを取得できる.)
const src = await prop.jsonValue();
// 結果を出力.
console.log(src);
}
ページをたどる
ページをたどるには、以下のいずれかの方法が必要です。
- waitForNavigationを使う
- URLを指定してgoto
waitForNavigation
waitForNavigationは、ページの遷移を待つ処理です。
遷移の処理は終わったのかどうかが分かりづらいので、conosole.logを入れてどこまで処理が進んだかを示すのも良い方法です。
waitで止まってしまうコード例
// 以下をやると waitで止まるので NG
console.log('--------------------goto');
await page.goto('http://www.livedoor.com/');
console.log('----------------------click');
await page.click('#topicsfb .topicsindex ul.emphasis li:nth-child(1) a');
// リンクをクリックしてから
console.log('---------------------wait');
await page.waitForNavigation({ waitUnitl: 'load' }); // 遷移され、loadするのを待つ
console.log('-----------------------------evaluate');
const h2Title = await page.evaluate(() => document.querySelector('h2.newsTitle').
textContent);
console.log('h2Title');なぜかと言うと、waitForNavigationを呼び出したときには、すでにclickによるページ遷移処理が終わっているためです。
そのため、Promise.allを使ってwaitForNavigationとclickを同時に呼び出すようにする必要があります。
OKな例
console.log('--------------------goto');
await page.goto('http://www.livedoor.com/');
console.log('--------------------wait and click');
await Promise.all([
page.waitForNavigation({ waitUnitl: 'load'}), //ここでページ遷移を待つ
// リンクをクリックする
page.click('#topicsfb .topicsindex ul.emphasis li:nth-child(1) a'),
]);
console.log('-----------------------------evaluate');
const h2Title = await page.evaluate(() => document.querySelector('h2.newsTitle').textContent);
console.log('h2Title');goto
今まで使ってきたように goto でも遷移先に移ることはできますが、なんとwaitForNavigation でclickを呼び出す方法と結果が異なる場合があります。
以下の3パターンを見てみます。
<a href="next-page.html">次のページへ</a> <!-- clickとgotoは同じ先になる --><a onclick="executeTransferPage();">次のページへ</a> <!-- clickとgotoは同じ先にならない --><a href="executeTransferPage();">次のページへ</a> <!-- clickとgotoは同じ先にならない -->2番め、3番目はJSの処理を呼び出したりしないといけないので処理を呼び出さないgotoでは遷移ができないということになってしまいます。
ページをたどる の例を示します。
console.log('----------------------------------------goto');
await page.goto('http://www.livedoor.com/');
await delay(1000); // スクレイピングする際にはアクセス間隔を1秒あける.
console.log('----------------------------------------wait and click');
await Promise.all([ // 次の処理たちを同時に呼び出す.
page.waitForNavigation({ waitUntil: 'load' }), // ページ遷移を待つ.
page.click('#topics_2602688 .rewrite_ab a'), // リンクをクリック.
]);
console.log('----------------------------------------evaluate');
const h1Title = await page.evaluate(() => document.querySelector('h1.topicsTtl').textContent);
console.log(h1Title);
console.log('----------------------------------------close');Let’s スクレイピング
この7つがスクレイピングを行うための視点です。あとは頭を使って以下に自分が必要な要素のみを取得し、どう表示させるかを考えて実施すること、その前提として、取得先サイトに迷惑をかけないようにすることを肝に銘じ、Let’s スクレイピングです!
