
Puppeteerシリーズ第4回。今回は、画像のダウンロードやスクリーンショット、ファイル読み書き、PDF化についてです。だんだん具体的になってきました。
おさらい
まずおさらいPuppeteerは、人形遣いという意味ですが、Webの世界では、Chromium(Chrome)を自動化するNode.jsで動作するライブラリのことです。
GoogleのChrome DevTools Teamが作りました。
ChromiumはGoogle Chrome、Opera、Microsoft Edgeなど多くのブラウザのベースになっています。
第1回は準備編、第2回はスクレイピング編、3回目はWeb動作編を書きましたのでご参考ください。

画像をダウンロード
画像のダウンロードができれば、かなり便利ですね。URLからファイル名を取得し、画像ダウンロードを行うというところまでを行ってみます。
Googleのロゴを取得
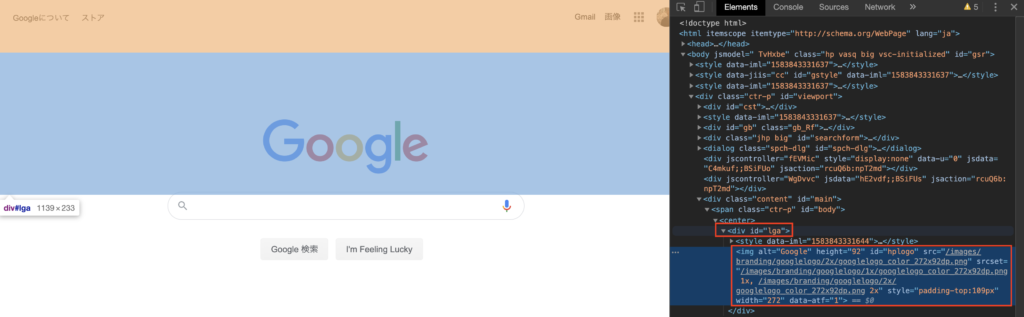
<div id=”lga”> の中の id=”hplogo” これを使います。
// 必要なモジュールをrequire
const puppeteer = require('puppeteer');
const fs = require('fs');
// The path module provides utilities for working with file and directory paths. It can be accessed using:
const path = require('path');
/**
* メインロジック.
*/
(async () => {
// Puppeteerの起動.
const browser = await puppeteer.launch({
headless: false, // Headlessモードで起動するかどうか.
slowMo: 50, // 指定のミリ秒スローモーションで実行する
});
// 新しい空のページを開く.
const page = await browser.newPage();
// view portの設定.
await page.setViewport({
width: 1200,
height: 800,
});
// 該当ページへ遷移する.
await page.goto('https://www.google.co.jp/');
// imgタグの取得. (取得した要素は ElementHandle というオブジェクトで取得できる。)
const image = await page.$('#lga img');
// 結果の出力.
// console.log(image);
// 取得したタグのsrc属性を取得する. (取得した属性は JSHandle というオブジェクトで取得できる.)
// 中身・・・JSHandle:https://www.google.com/images/branding/googlelogo/2x/googlelogo_color_272x92dp.png
const src = await image.getProperty('src');
// console.log(src);
// JSHandleオブジェクトの内容をjsonValueで取り出す. (この場合は文字列がsrcに指定しているurlを取得できる.)
// JSONの中身・・・ // 中身・・・https://www.google.com/images/branding/googlelogo/2x/googlelogo_color_272x92dp.png
const targetUrl = await src.jsonValue();
console.log(`targetUrl=${targetUrl}`);
// URLで形式で取得できたパスのファイル名部分のみを取り出す.
// / で分割して、pop()で最後の要素を取得。
const filename = targetUrl.split('/').pop();
console.log(`filename=${filename}`);
// 以下は、取得したファイルをローカルにダウンロードする手順
// ローカルのフルパス __dirname は、Node.jsの予約語で現在のjsファイルのあるフォルダを示す。
const localfilefullpath = path.join(__dirname, filename);
console.log(`localfilename=${localfilefullpath}`);
// page.gotoで先程取得したターゲットURLを開き、それをviewSourceに格納
const viewSource = await page.goto(targetUrl);
// fs(fileSystem)でローカルのフルパスに出力。
fs.writeFile(localfilefullpath, await viewSource.buffer(), (error) => {
// エラー出たらエラーをログに出す
if (error) {
console.log(`error=${error}`);
return;
}
// エラー出なかったらログに文字列を表示させる。
console.log('The file was saved!');
});
// ブラウザの終了.
await browser.close();
})();ローカルにダウンロードするためにpathを使うので、requireし、ダウンロードしたものをファイルへの読み書きを行うのでfsをrequireしています。
該当ページの該当画像のsrc属性を取得し、jsonValueで取り出します。そしてURLの形で取得したパスを分割し、ローカルにダウンロードします。
エラーの出力も記載します。
これで画像がダウンロードできるようになります。
画面をキャプチャ
キャプチャはPuppeteerの標準機能であります。
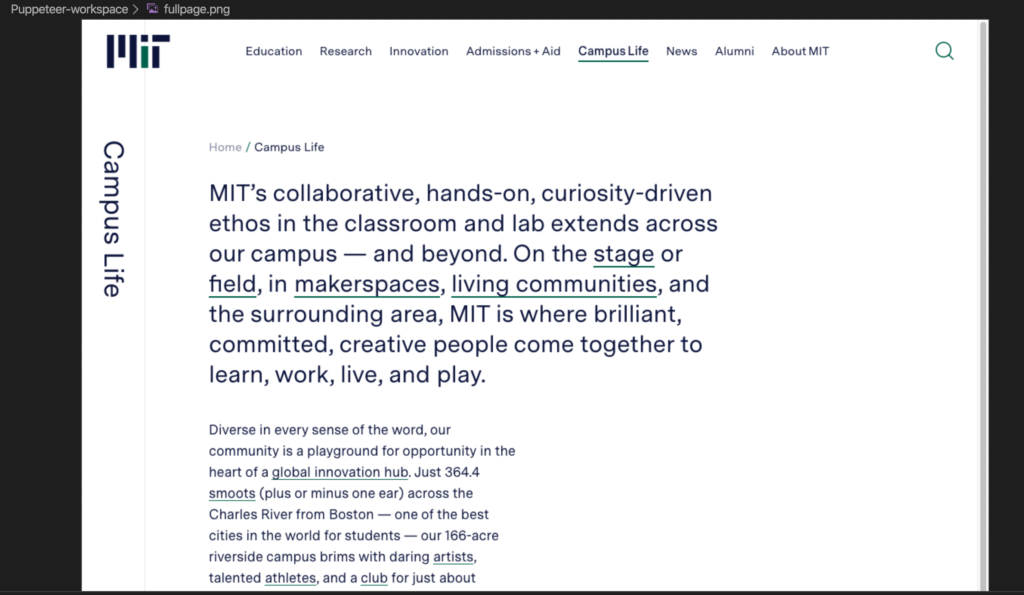
物理的なディスプレイのサイズに制約されず、全画面キャプチャが撮れます。page.screenshotで指定するだけです。
await page.screenshot({ path: 'fullpage.png', fullPage: true });page.screenshotの第2引数に、fullpage.trueを指定することでキャプチャを撮ります。
const puppeteer = require('puppeteer');
/**
* メインロジック.
*/
(async () => {
// Puppeteerの起動.
const browser = await puppeteer.launch({
headless: false, // Headlessモードで起動するかどうか.
slowMo: 50, // 指定のミリ秒スローモーションで実行する.
});
// 新しい空のページを開く.
const page = await browser.newPage();
// view portの設定.
await page.setViewport({
width: 1200,
height: 800,
});
await page.goto('https://www.mit.edu/campus-life/');
// await page.waitForNavigation({waitUntil:'networkidle2', timeout:5000})
// .catch(e => console.log('timeout exceed. proceed to next operation'))
await page.screenshot({ path: 'fullpage.png', fullPage: true });
// ブラウザを終了.
// await browser.close();
})();
こんな感じで、スクリーンショットを撮れます。
ファイルを読み書き
Puppeteerでスクレイピングして取得したデータをファイルに書き込んだり、過去のファイルを比較するときなどに、ファイル読み書きをする事があります。
Node.jsにある、おなじみfsモジュールを使います。
const fs = require('fs');書き込み
fsモジュールのwriteFile()メソッドを使うことで書き込みを行うことができます。
writeFile(ファイルパス, 書き込みたい内容, コールバック関数);※文字コード指定無しの場合は、UTF-8になる。
※第3引数は、書き込み処理の結果をコールバック関数として定義。
※ファイルの処理なので、エラー処理を行う必要がある。
最小構成はこちらになります。
const fs = require('fs');
const content = 'データファイルの想定';
fs.writeFile(path.join(__dirname, 'data.txt'), content, (error) => {
if (error) {
console.log('ファイル書き込みエラーです');
console.log(error);
} else {
console.log('ファイルに書き込みました');
}
});読み込み
fsモジュールの readFile()メソッドを使うことで読み込みを行うことができます。
readFile(ファイルパス, コールバック関数);※コールバック関数は、errorとdataをパラメータとして受け取る処理を指定する。
※dataはBuffer(Node.jsでバイナリデータを扱うためのオブジェクト)のため、文字として扱うためにStringにする = doString()
最小構成はこちらになります。
const fs = require('fs');
fs.readFile(path.join(__dirname, 'data.txt'), (error, data) => {
if (error) {
console.log('ファイル書き込みエラーです');
console.log(error);
return;
}
console.log('読み込んだファイルの内容を表示します↓');
console.log(data.toString());
}
});Shift_JISのファイルの書き込み
Node.jsではShift_JISはサポートしていないため、iconv-liteモジュールのencodeメソッドを利用して対応します。
const fs =require('fs');
const iconv =require('iconv-lite');
const content = 'データファイルの想定';
fs.writeFile(path.join(__dirname, 'shift-jis.txt'), iconv.encode(content, 'Shift_JIS'), (error) => {
console.log(error);
if (error) {
console.log('ファイル書き込みエラー');
} else {
console.log('ファイルに書き込みました');
}
});Shift_JISのファイルの読み込み
こちらも iconv-liteモジュールのencodeメソッドを利用して対応する。
読み込んだdataに対して、Buffer.fromを呼び出し、バイナリデータを取り出す → iconv.decode(buffer, ‘Shift_JIS’)で取り出したバイナリデータをShift_FISとして文字列化します。
iconv-liteモジュールが入っていない場合は、npmなどでインストールしておく必要があります。
npm install iconv-liteソースコードはこちらになります。
const fs =require('fs');
const iconv =require('iconv-lite');
fs.readFile(path.join(__dirname, 'shift-jis.txt'), (error, data) => {
if (error) {
console.log('ファイル読み込みエラー');
console.log(error);
return;
}
console.log('読み込んだファイルの内容を表示↓');
const buffer = Buffer.from(data);
const content = iconv.decode(buffer, 'Shift_JIS');
console.log(content);
}
});CSVファイルを出力
CSVはどんな人でも使ったことがあるファイル形式です。項目間はカンマ区切り、項目中の数字、文字、改行などがある場合には “”で区切ります。
CSVの規格については、知っておくと良いです。

CSVを作成する
dataオブジェクトの多次元配列を作り、stringifyで作ったデータオブジェクトを1つながりのテキスト文字列に変換する。
という方法をとります。
まずはcsv-stringifyをnpmなどでインストールしましょう。
npm install csv-stringify
変換した文字を、fsを使って指定したファイル名に出力。
※取得データには項目中の’があったり、改行コードがあったりするのでそれを取り除く必要もあったりする。
// csv-stringifyをrequire
const stringify = require('csv-stringify');
const iconv = require('iconv-lite');
const fs = require('fs');
const path = require('path');
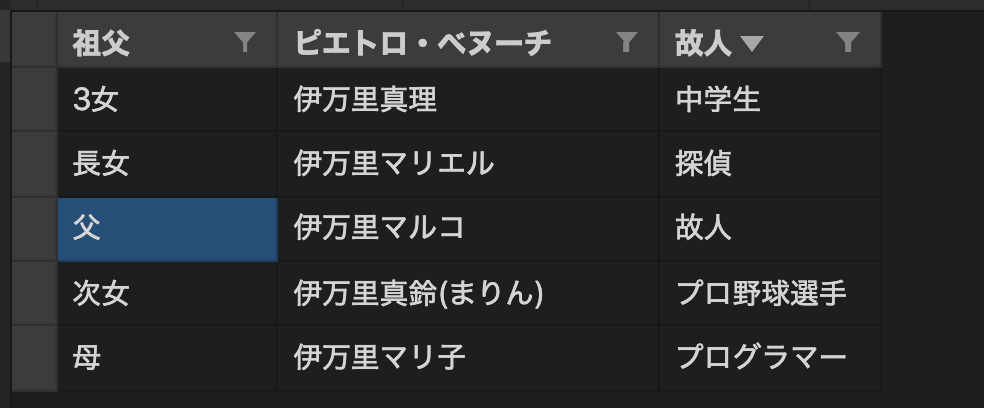
const data = [
['祖父', 'ピエトロ・ベヌーチ', '故人'],
['父', '伊万里マルコ', '故人'],
['母', '伊万里マリ子', 'プログラマー'],
['長女', '伊万里マリエル', '探偵'],
['次女', '伊万里真鈴(まりん)', 'プロ野球選手'],
['3女', '伊万里真理', '中学生'],
]; // CSVに保存する情報
// CSVに出力する処理.
// data(多次元配列)
stringify(data, (error, csvString) => {
// ファイルシステムに対してファイル名を指定し、ファイルストリームを生成する.
const writableStream = fs.createWriteStream(path.join(__dirname, 'Forget-me-not.csv'));
// csvStringをUTF-8で書き出す.
writableStream.write(iconv.encode(csvString, 'UTF-8'));
});ちなみに、VSCodeの拡張機能「Excel Viewer」をインストールしておくと、Spreadsheet風に見ることができます。
PDFファイルを出力
Pageオブジェクトのpdf()メソッドを呼び出すことでPDFは出力できます。
※pdf()メソッドは、headlessモードでないとエラーになるらしいので、注意。
また、印刷用のデザインがプレビューされるページもあります。これは、CSSを切り替えてプレビューを見せているものですがそんな印刷用のデザインで取得したい場合にも、やり方があります。
emulateMediaを呼び出せばよいです。
// 画面表示用
await page.emulateMedia('screen');
// 印刷用
await page.emulateMedia('print');const puppeteer = require('puppeteer');
const path = require('path');
const delay = require('delay');
(async () => {
// Puppeteerの起動.
const browser = await puppeteer.launch({
args: ['--lang=ja'],
// headless: false, // page.pdfはHeadlessモードで実行する必要あり.
slowMo: 50,
});
// 新しい空のページを開く.
const page = await browser.newPage();
// view portの設定.
await page.setViewport({
width: 1200,
height: 800,
});
// 日経電子版を見に行く
console.log('----------------------------------------goto');
await page.goto('https://www.nikkei.com/');
await delay(1000); // スクレイピングする際にはアクセス間隔を1秒あける.
// 画像を取得しクリックする
console.log('----------------------------------------click');
await page.screenshot({ path: path.join(__dirname, '001-before.png') });
await Promise.all([
page.waitForNavigation({ waitUntil: 'load' }),
page.click('.k-card__content a'),
]);
await delay(1000); // スクレイピングする際にはアクセス間隔を1秒あける.
console.log('----------------------------------------emulate');
await page.emulateMedia('screen');
await page.screenshot({ path: path.join(__dirname, '002-screen.png') });
console.log('----------------------------------------emulate');
await page.emulateMedia('print');
await page.screenshot({ path: path.join(__dirname, '003-print.png') });
console.log('----------------------------------------pdf');
await page.pdf({ path: path.join(__dirname, 'nikkei-top.pdf'), format: 'A4' });
await page.screenshot({ path: path.join(__dirname, '004-after.png') });
console.log('----------------------------------------close');
await browser.close();
})().catch((e) => {
console.log(e);
});
最後に
ここまでくれば、色々やりたいことの実現に近づいてきた感じです。
複雑な部分もありますが、やり方があるわけですからやり方だけ守ってあれこれやってみればシステムは動いてくれるはずです。
まずは試しに身近なサイトで少しやってみると「これでいいんだ!」という感動がわかります。
Puppeteer活用してみましょう!
